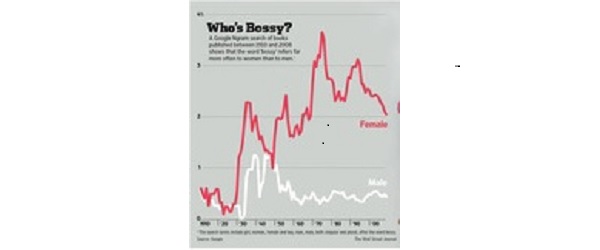
The Internet theoretically is a statistician’s dream. Let’s hope it’s not an nightmare. In our March 10, 2014 post about the irreproducible results of an Ngram search we warned that nothing prevents Google from changing their definitions or conventions … and not telling us about them. But since they tell us precious little, it seems wise not to base important conclusions or critical decisions solely on any relatively lengthy history of the counts data. And that “relatively lengthy” may be even as short as a month or a quarter, because it is easy for Google to change their mind and their software. This was brought to our attention in the December 21 New York Times by economist Seth Stephens-Davidowitz, who apparently makes a career analyzing counts produced by Google searches of certain key words or survey data collected by other surveyers. Overall, the New York Times article showed mostly upbeat behavior during the holiday season, which one would hope for. Whether the annual trends are accurate or not, likely only Google knows for sure. And we are not opining that Google is doing anything malicious in making their changes; they may all be done with the goal of improved accuracy and usability. But without more transparency we will never know.